Grounding Agent Memory in Contextual Intent
Loading PDF...
Abstract
Deploying large language models in long-horizon, goal-oriented interactions remains challenging because similar entities and facts recur under different latent goals and constraints, causing memory systems to retrieve context-mismatched evidence. We propose STITCH (Structured Intent Tracking in Contextual History), an agentic memory system that indexes each trajectory step with a structured retrieval cue, contextual intent, and retrieves history by matching the current step’s intent. Contextual intent provides compact signals that disambiguate repeated mentions and reduce interference: (1) the current latent goal defining a thematic segment, (2) the action type, and (3) the salient entity types anchoring which attributes matter. During inference, STITCH filters and prioritizes memory snippets by intent compatibility, suppressing semantically similar but context-incompatible history.
For evaluation, we introduce CAME-Bench, a benchmark for context-aware retrieval in realistic, dynamic, goal-oriented trajectories. Across CAME-Bench and LongMemEval, STITCH achieves state-of-the-art performance, outperforming the strongest baseline by 35.6%, with the largest gains as trajectory length increases. Our analysis shows that intent indexing substantially reduces retrieval noise, supporting intent-aware memory for robust long-horizon reasoning.
Key Findings
State-of-the-Art Performance
STITCH consistently outperforms 13 strong baselines—including long-context LLMs (GPT-4.1-mini, GPT-5-mini) and structured memory systems (GraphRAG, RAPTOR)—across both CAME-Bench and LongMemEval benchmarks.
Scales to Long Horizons
While standard baselines degrade as trajectory length increases, STITCH remains robust. On the 'Large' subset (~408k tokens), it outperforms the strongest baseline by 35.6%, eliminating the 'lost-in-the-middle' phenomenon.
Eliminates Retrieval Noise
By indexing steps with Contextual Intent, STITCH suppresses 'distractors'—evidence that is semantically similar but belongs to a different goal or time—ensuring the agent retrieves the right fact in the right context.
Thematic Scope is Critical
Ablation studies reveal that 'Thematic Scope' (goal-oriented segmentation) provides the largest performance gain, effectively partitioning long interaction histories into manageable, coherent episodes.
* Metrics shown: Macro-F1 for CAME-Bench, Accuracy for LongMemEval.
Methodology (STITCH)
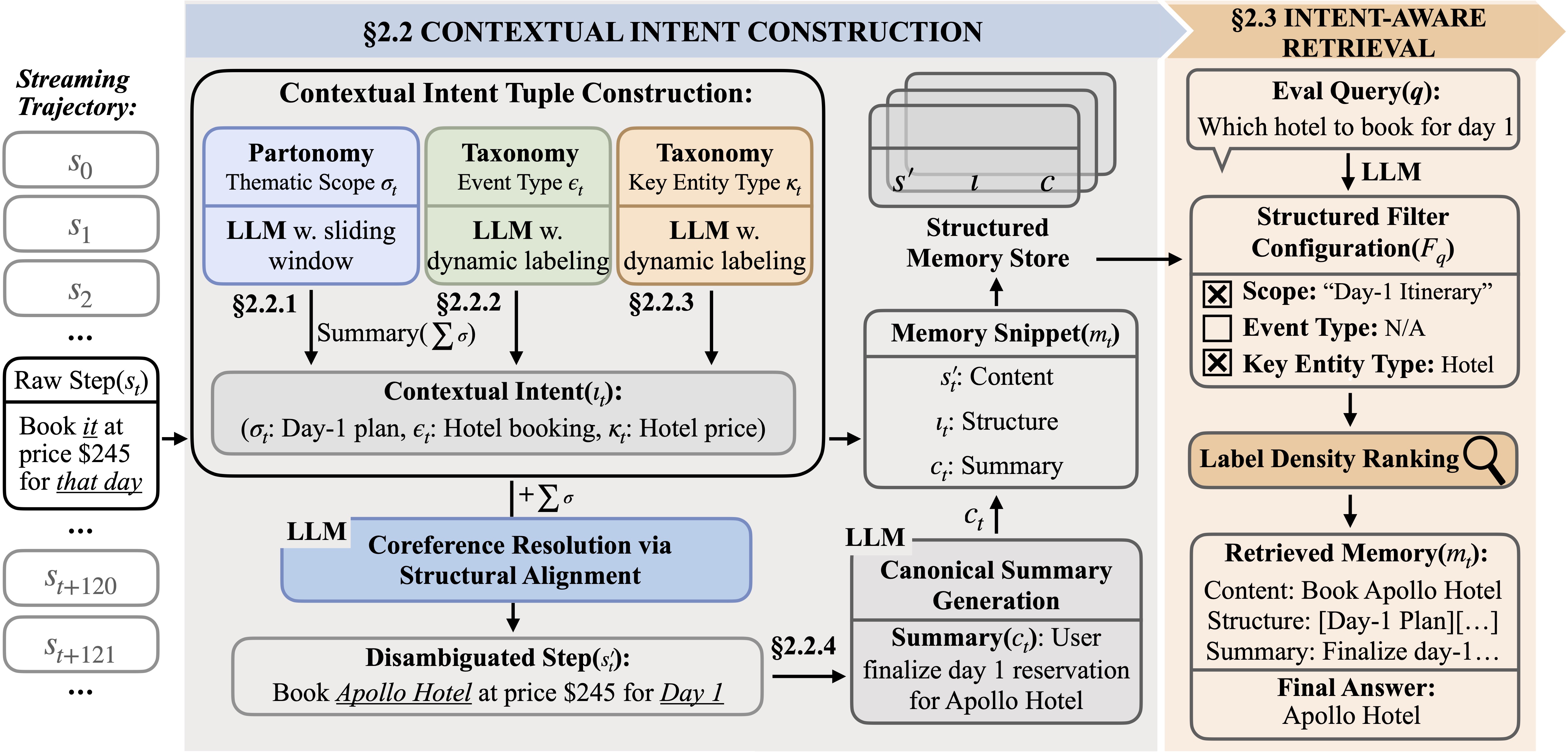
Standard retrieval relies on semantic similarity, which fails when similar facts recur in different contexts. STITCH (Structured Intent Tracking in Contextual History) solves this by indexing every trajectory step with a structured retrieval cue called Contextual Intent. Grounded in Event Structure Theory, STITCH organizes memory not as a flat list, but as a structured history of goals, actions, and entities.
Core Concepts
The Schema: Contextual Intent
We index each step with a tuple ιt = (σt, ϵt, κt):• Thematic Scope (Partonomy): A stable label tracking the current high-level goal (e.g., “Day 2 Itinerary”).
• Event Type (Taxonomy): An action label capturing the operation performed (e.g., “Comparison”, “Debugging”).
• Key Entity Types (Taxonomy): The schema class identifying relevant attributes (e.g., “Price”, “Error Code”).
Online Induction (Domain Agnostic)
STITCH does not require a pre-defined ontology. It induces these cues online from the streaming trajectory. It uses sliding windows to detect goal shifts and maintains dynamic vocabularies for event and entity types that evolve as the agent encounters new tasks.
Structural Coreference Resolution
Implicit references are a major cause of retrieval failure. STITCH leverages the induced structure to resolve referencesbefore storage. For example, an ambiguous step like "Book it" is rewritten to "Book the Apollo Hotel" by aligning it with the active thematic scope.
Retrieval: Structure First, Semantics Second
At inference time, STITCH translates a query into a structured filter. We employ Label Density Ranking, which strictly prioritizes memory snippets that match the intent structure first. Semantic similarity is used only as a tie-breaker, effectively filtering out contextually irrelevant distractors.
System Architecture
Loading...
The Benchmark: CAME-Bench
Open Benchmark Explorer →Existing benchmarks often rely on unrealistic turn-taking or independent topics. To rigorously test context-aware retrieval, we introduce CAME-Bench. It features continuous, goal-oriented trajectories constructed with High Contextual Interference—where recurring entities and interleaved goals create significant ambiguity.
Design Principles
Symbolically Grounded Consistency
We decouple planning from generation. A symbolic planner ensures logical causal consistency over long horizons (e.g., Travel Planning itineraries and Debate argumentation), guaranteeing that every state transition is valid before it is rendered into natural language.
Controlled Semantic Interference
We utilize a closed-world environment to densely reuse static entities. This forces models to disambiguate fine-grained context (e.g., the same hotel appearing in three different potential plans) rather than relying on unique keywords.
Dynamic Referential Ambiguity
Interactions are not strictly turn-taking. Requests are often interleaved, deferred, or implicitly referenced later (e.g., "Use the evidence from that previous counter-argument"), requiring the memory system to track state updates rather than static facts.
Evaluation Capabilities
We evaluate four distinct capabilities required for robust long-horizon agents:
1. Incremental Memory Revision
Can the agent track state changes?
Ex: Tracking a restaurant candidate list as items are added and subsequently rejected across turns.
2. Context-Aware Factual Recall
Can the agent disambiguate similar facts?
Ex: Retrieving the hotel price specifically for "Day 2", distinguishing it from the "Day 1" price.
3. Multi-Hop Reasoning
Can the agent resolve implicit references?
Ex: Identifying what "that reservation" refers to, then retrieving its associated attributes.
4. Information Synthesis
Can the agent aggregate scattered info?
Ex: Reconstructing a full 3-day itinerary from bookings scattered across 500 turns of dialogue.